随着数据日益增加,项目需要进行分库分表来分摊压力,为了保证数据ID唯一,必须有一套适配当前分库分表的分布式ID生成方案,而这套方案必须具备以下条件:
所以本文就基于上述要求针对市面主流的几种分布式ID算法的特点和适用场景展开深入探讨。

UUID有着全球唯一的特性,只需一行简单的代码,即可快速生成一个UUID:
public static void main(String[] args) {
log.info("uuid:{}", UUID.randomUUID());
}输出结果:
uuid:9fea8ab3-0789-4719-aa70-8849cbc59916符合全局唯一、高性能、高并发、高可用、易用的特性。但是它却有以下缺点:
所以UUID虽在性能、唯一性、可用性上有着保证,但其生成结果会加剧数据库的负担,所以不是很推荐用作分布式ID。
我们也可以专门使用一张数据表生成唯一自增的id,通过数据库auto_increment特性自增唯一且有序的分布式ID:
CREATE TABLE id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
);这种做法优点就是实现简单且单调递增,ID也是数值类型,所以查询速度很快,但它也有以下缺点:
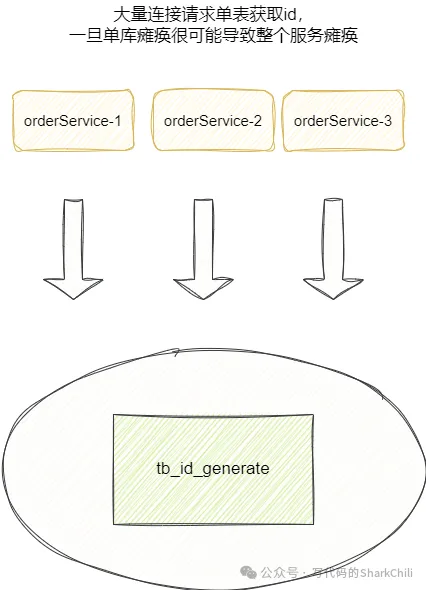
针对上述问题,我们提出使用多库多表生成分布式ID以保证高可用,例如我们现在就使用双主模式,每个库分别存放一张id分配表(id_allocation ),表1的id从1开始,表2的id从2开始,各自的步长都为2:
-- ID分配表1,从1开始自增,步长为2
CREATE TABLE db1.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=1;
-- ID分配表2,从2开始自增,步长为2
CREATE TABLE db2.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=2;为了保证压力均摊,我们可以针对服务采用轮询或者哈希算法请求不同的数据库获取唯一ID:
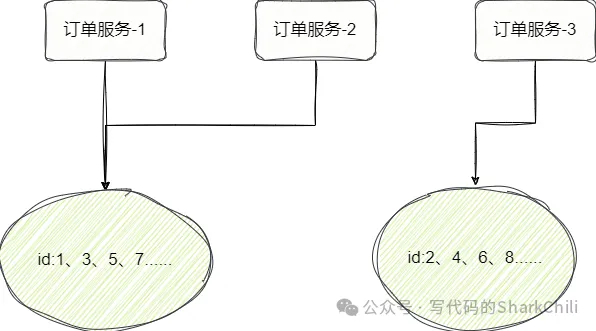
该方案很好的解决的DB单点问题,但是仅仅为了全局id而徒增这么多的硬件服务器确实是有些许浪费。
号段式分布式ID生成是当下比较主流的实现方案之一,它的整体思路是在专门建立一张数据表划分当前业务的ID分配段,每次加载一批号段到内存中,然后所有的服务都从这个号码段中获取ID,直至这个号码段用完,然后再到数据库中再划动一批到内存中使用,对应的建表SQL如下所示:
CREATE TABLE id_allocation (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前已用最大id',
step int(20) NOT NULL COMMENT '号段分配步长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)我们假设现在有一个订单服务要采用号段式进行ID分配,我们在这张表中初始化订单服务的数据,可以看到订单服务初始化的数据,max_id为0,即表示当前这个业务还未分配任何id,业务类型为1,step为1000,即代表每次有服务来请求时就分配1000个id段给请求服务,而version则是保证多服务请求数据一致性的乐观锁版本号:
INSERT INTO id_allocation (id, max_id, step, biz_type, version) VALUES (1, 0, 1000, 1, 0);到数据查询当前业务的号码段,查询数据库得到结果是max_id为0以及step为1000,这意味着当前这个业务的id已经用到了0(还未使用过),而可用范围为1000,所以号码段为[max_id+1,max_id+step]即1~1000,将数据库加载到数据库之后,携带版本号将数据的max_id更新为max_id+step,如此一来下次id分配就从1000开始:
update table set max_id=max_id+step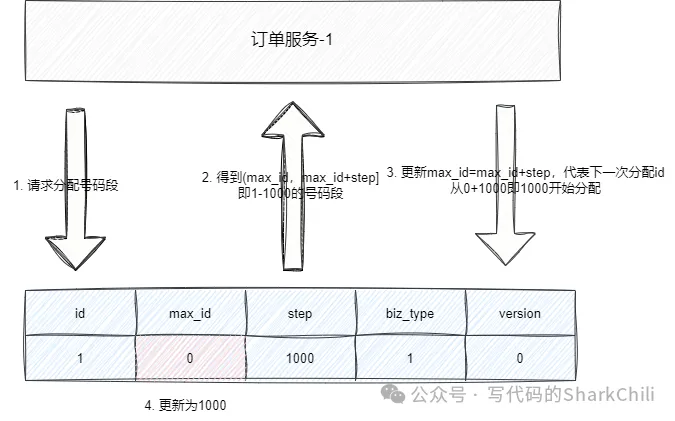
为了避免因为服务崩溃等情况导致内存中的号码段丢失,我们需要如下两个步骤的处理避免ID冲突:
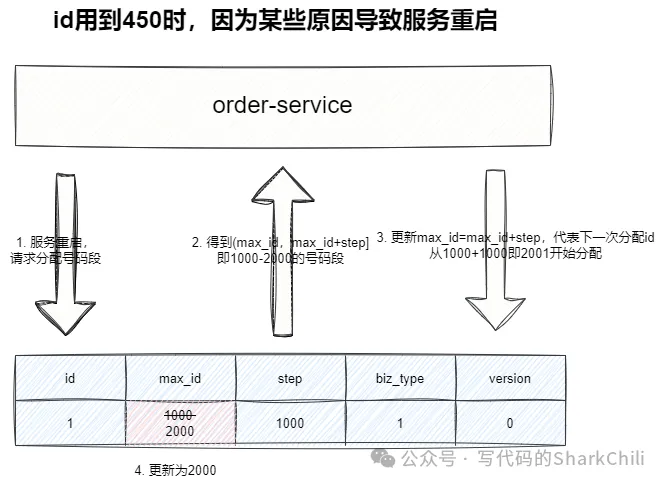
可以说这种方案通过数据库结合内存缓冲了数据库的压力,既保证的唯一性,又能够抗住高并发,对于扩容,我们也可以通过在数据库中增加配置,以调整id范围。而它的缺点也很明显,它很可能因为服务宕机或者内存丢失的原因,导致一段id全部丢弃导致一定的号码段浪费。
按照redis官方的说法,redis单机qps为8~10w(8C16G服务器)并且因为单线程的缘故,redis也能很好的保证id自增的原子性:
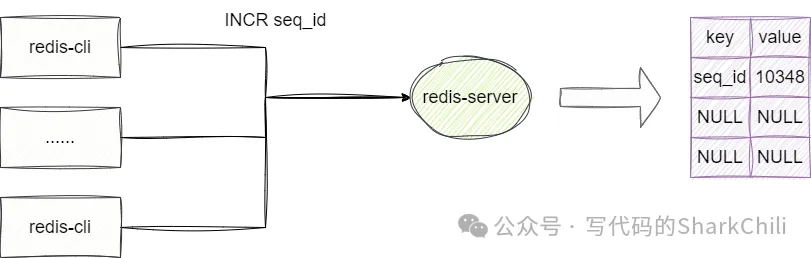
所以我们也可以尝试通过redis原子操作获取唯一id:
127.0.0.1:6379> set seq_id 1
OK
127.0.0.1:6379> INCR seq_id
(integer) 2
127.0.0.1:6379> INCR seq_id
(integer) 3
127.0.0.1:6379> INCR seq_id
(integer) 4
127.0.0.1:6379>当然这种方案也有着一定的缺点:
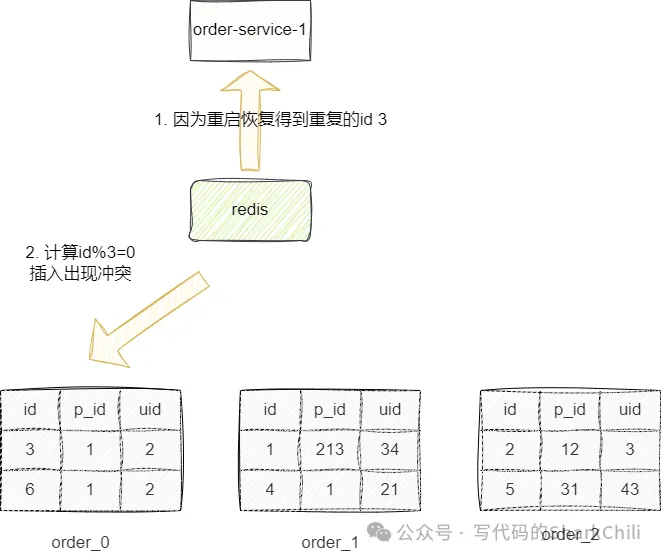
所以我们建议通过redis混合持久化机制结合redis高可用架构保证分布式id生成的可靠性,并在业务处理上对这类id冲突进行一定的兜底处理。
(1) 雪花id算法介绍
雪花算法是twitter开发是一中id生成算法,它是由如下几个因子构成:
对应结构图如下所示:

通过雪花算法在毫秒级情况下可以生成大量id,性能出色,且是有序自增的,类型也是long类型,且包含日期和workerid等具备基因特性的因子,可以满足大部分业务场景的需求,只不过雪花算法也有一些考虑的问题:
举个例子:在商城下单后,我们通过雪花算法生成唯一订单号,根据hash算法id%table 得到分表名称。这样的话,我们通过订单号可以快速定位到分表并查询到数据。但是从用户角度来说,他希望通过自己的uid定位到订单号就无迹可寻了,所以针对多分片键的场景使用雪花算法可以需要结合基因法进行一番改造。
(2) 使用示例
以下是开源工具类hutool提供的雪花工具类,只需两行代码即可生成唯一键。
@Slf4j
public class Main {
public static void main(String[] args) {
Snowflake snowflake = new Snowflake();
log.info("snowflake:{}", snowflake.nextId());
}
}输出结果如下:
12:23:24.412 [main] INFO com.sharkchili.distIdFactory.Main - snowflake:1740226920726044672为了验证唯一性,笔者在单位时间内连续生成100w的雪花id:
@Slf4j
public class Main {
public static void main(String[] args) {
Set<Long> idSet = new HashSet<>();
Snowflake snowflake = new Snowflake();
for (int i = 0; i < 100_0000; i++) {
idSet.add(snowflake.nextId());
}
log.info("idSe sizet:{}", idSet.size());
}
}从输出结果来看,常规用法下没有出现id碰撞:
12:35:27.167 [main] INFO com.sharkchili.distIdFactory.Main - idSe sizet:1000000(3) 雪花id与时钟回拨问题
我们都知道雪花id是通过时间戳结合自增序列等方式保证分布式id的唯一性,但是这种方案其实也存在一定的缺陷。
我们假设这样一个场景,我们现在的雪花id工具类在服务器1上,所以在这台服务器上的id对应的机器id和服务id都是相等的。唯一性都是通过时间戳+自增序列来保证,试想一下如果我们在雪花id工具工作期间,将操作系统时间回拨,这就可能出现之前用过时间戳+自增序列重复,进而导致数据入库失败:
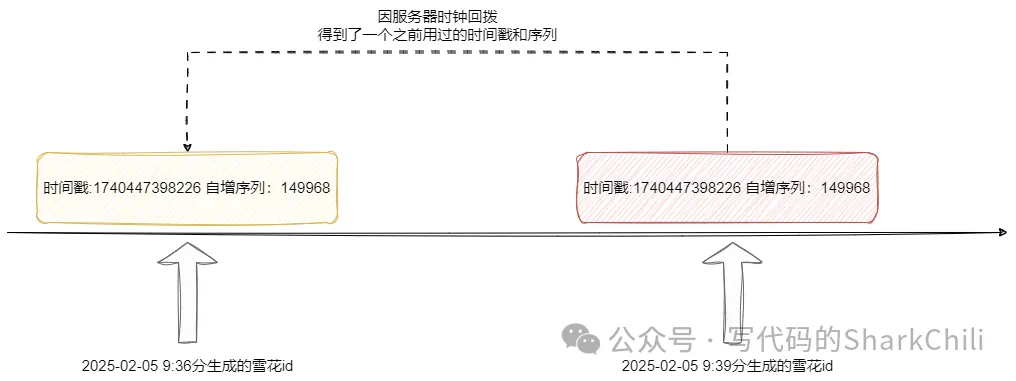
对此著名的java工具类库hutool就做的很好,它会在每次生成雪花id时,维护一下生成的时间戳,每次生成时通过比对本次时间戳和上次时间戳的差值判断是否出现时钟回拨:
public synchronized long nextId() {
long timestamp = genTime();
//判断本次回拨的时间是否大于timeOffset(默认2s),即回拨超过2s就报错
if (timestamp < this.lastTimestamp) {
if (this.lastTimestamp - timestamp < timeOffset) {
// 容忍指定的回拨,避免NTP校时造成的异常
timestamp = lastTimestamp;
} else {
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
//......
//维护本次使用的时间戳
lastTimestamp = timestamp;
return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}(4) 基于雪花算法下的带有基因的分布式ID
如上所说,雪花算法中时间戳和workerId这几个字段都算是有迹可循的因子,作为特定基因可以保证分库分表不同维度的查询需求,例如我们现在有这样一个场景:
由上文提及雪花算法有41位代表生成id的时间戳,所以针对时间分表读写都是可以实现的。而上述需求中有3个库,按照雪花算法的规则,它有5位的workerid,我们完全可以用这几个bit存储当前数据所存储的库源信息。
我们都知道分库分表主要是为了解决并发请求和海量数据,所以针对这样的业务场景,我们势必会针对该场景设计出相应的集群节点,我们假设当前集群有3个节点,按照分库分表的设计,我们可以将分库分表业务对应的服务程序各自初始化一个雪花id生成器,服务的workerId分别对应1、2、3。
假设某用户请求到的服务1且日期是2025.1.25,由于服务器的workerId为1,所以雪花id的机器id就标记为1,同时基于当前时间点得出41位的时间戳为2025.1.25也就是分表-1,所以我们数据就会写入到库1的分表1中:
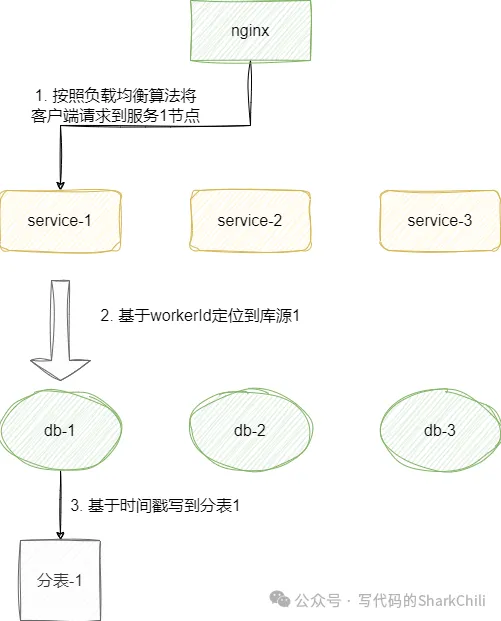
因为id藏有库源信息和日期信息,后续定位也非常方便,就像下面这段代码示例:
//指明workerId为1,即当表当前服务的数据全部存入库1
Snowflake snowflake = new Snowflake(1);
long id = snowflake.nextId();
//后续数据读写都可以基于id定位到
DateTime date = DateUtil.date(snowflake.getGenerateDateTime(id));
log.info("分布式id对应的库源:{} 日期:{}", snowflake.getWorkerId(id), date);对应的我们也给出这段代码的输出结果:
01:13:43.446 [main] INFO com.sharkChili.runner.ESRunner - 分布式id对应的库源:1 日期:2025-01-25 01:13:43如果觉得博客文章对您有帮助,异或土豪有钱任性,可以通过以下扫码向我捐助。也可以动动手指,帮我分享和传播。您的肯定,是我不懈努力的动力!感谢各位亲~


